Recruitment has always been a people business, but the engine running behind it is increasingly anything but human.
Machine learning, a branch of artificial intelligence that enables systems to learn from data and improve over time without being explicitly programmed, is quietly reshaping how organisations find, evaluate, and hire talent.
From powering AI resume screening to surfacing the strongest matches in an applicant pool, machine learning is doing in seconds what once took recruiters days. It is making data-driven recruiting less of an aspiration and more of a daily operational reality for hiring teams of every size.
But machine learning in recruitment is not without its complications, particularly around bias in hiring. This guide unpacks how it works, where it adds genuine value, and what hiring teams need to watch out for.
The core metric governing machine learning effectiveness in recruitment is Screening Model Precision Rate: the proportion of candidates that a machine learning screening model identifies as qualified who are genuinely qualified when assessed by a structured human evaluation.
Screening Model Precision Rate (%) = (True Positive Predictions / (True Positive + False Positive Predictions)) x 100
High-performing recruitment ML models achieve Precision Rates above 82%. Industry average for first-generation models sits around 63%. The gap is explained primarily by training data quality and outcome definition clarity, not by model architecture.
What is Machine Learning in Recruitment?
Machine learning in recruitment is the application of statistical learning algorithms to talent acquisition and workforce management problems, enabling systems to improve their prediction accuracy over time by learning from historical data rather than following explicitly programmed rules. In practical terms, this means recruitment systems that can screen resumes against role requirements at scale, predict which candidates are likely to accept offers, identify employees at risk of attrition before they resign, and surface candidate profiles for open roles without a recruiter constructing a manual search.
The foundational distinction between machine learning and rules-based automation in recruitment is adaptability. A rules-based screening system applies fixed criteria: candidates with X years of experience and Y certification pass; those without them do not.
A machine learning screening system learns the relationship between hundreds of candidate variables and successful hire outcomes, weighting criteria based on what the data shows actually predicts performance rather than what hiring managers believe should predict it. The difference in screening accuracy between the two approaches is significant and grows over time as the model trains on more outcome data.
Why Machine Learning Is a Strategic Priority in Modern Talent Acquisition?
The talent acquisition function produces one of the most data-rich decision environments in any organization, yet for most of the industry’s history, the decisions made within it have been among the least data-informed. A hiring manager’s interview judgment, a recruiter’s candidate assessment, a sourcer’s search filter choices: all of these are high-stakes decisions made primarily on intuition, pattern matching from personal experience, and cognitive shortcuts that behavioral research has consistently shown to be unreliable predictors of actual hire quality.
Machine learning in recruitment addresses this gap directly. By training models on historical hiring data, including which candidates were screened in, which advanced through interviews, which received offers, which accepted, and which performed well at 12-month review, organizations can build predictive systems that encode the patterns from thousands of past decisions rather than relying on the pattern recognition capacity of a single recruiter or hiring manager. The improvement in screening accuracy is not modest. A well-trained machine learning screening model typically achieves 2.5 to 3.5 times the predictive accuracy of unstructured human screening for equivalent candidate populations.
The ROI case for machine learning in recruitment is grounded in volume and consistency. For an organization processing 50,000 annual applications across all roles, reducing the average time spent on manual screening from 6 minutes to 45 seconds per application through ML-powered automated screening saves approximately 7,800 recruiter hours per year. At an average recruiter fully loaded cost of $85 per hour, that is a direct capacity saving of $663,000 annually, before accounting for the quality improvement from more consistent screening criteria.
The concrete failure scenario is equally instructive. A large financial services firm implements an ML-powered resume screening tool trained on 5 years of historical hiring data. Within 18 months, the tool is screening over 80% of applications with high accuracy and speed. But the firm’s quality-of-hire metrics for the ML-screened cohort are running 12% below the firm’s historical average. Investigation reveals the root cause: the training data contained five years of hiring decisions made under a previous leadership team that had a documented pattern of screening out candidates from non-target universities.
The ML model learned, with high accuracy, to replicate a discriminatory hiring pattern that the firm had already committed to eliminating. The model was not wrong in the statistical sense; it was precisely right about the wrong thing. Clean, audited, bias-reviewed training data is not a prerequisite for an ML model; it is a prerequisite for a useful one.
For TA leaders, the practical implication is that machine learning in recruitment is not a technology purchase; it is a data strategy decision. The organizations that will extract genuine competitive advantage from ML-powered talent acquisition are those that invest as seriously in data quality, outcome measurement, and model auditing as they do in model selection and vendor evaluation.
Your Resume Isn’t Getting Read
Let’s Get That Fixed!
75% of resumes get auto-rejected. avua’s AI Resume Builder optimizes formatting, keywords, and scoring in under 3 minutes, so you land in the “yes” pile.
The Psychology Behind Machine Learning in Recruitment
Automation Bias and Over-Reliance on Model Outputs
When machine learning models are introduced into recruitment workflows, a predictable and well-documented psychological shift occurs: recruiters and hiring managers begin treating model outputs as authoritative rather than as one signal among many. This automation bias, the tendency to over-weight automated recommendations relative to human judgment, is particularly pronounced in high-volume screening environments where the speed of ML-generated scores creates implicit pressure to accept them without challenge. Organizations that introduce ML screening without explicit training on appropriate human override behavior see automation bias emerge within weeks of deployment.
Algorithmic Aversion and Credibility Challenges
The opposite failure mode is equally common. Hiring managers who receive an ML-generated candidate ranking that conflicts with their own intuitive assessment frequently dismiss the model output rather than investigating why the discrepancy exists. This algorithmic aversion, the tendency to reject automated recommendations when they conflict with personal judgment, is particularly strong among experienced hiring managers who have high confidence in their own evaluation capabilities. The resolution is not to suppress the aversion but to create structured processes for investigating disagreements between model output and human judgment, which frequently surface genuine problems in either the model’s training data or the human’s evaluation approach.
Trust Calibration Over Time
Research on human-AI collaboration in decision-making environments consistently shows that the most effective integration of machine learning tools into recruitment workflows occurs when organizations invest in explicit trust calibration. This means giving recruiters and hiring managers structured feedback on when model outputs were right and when they were overridden by human judgment and what the outcomes were in each case. Organizations that run these calibration exercises quarterly see measurably better human-AI decision integration than those that deploy ML tools and assume the working relationship will self-organize.
Machine Learning vs. Related Recruitment Technology
| Technology Type | Decision Basis | Learning Capability | Accuracy Over Time | Human Override Role |
|---|---|---|---|---|
| Machine Learning Models | Statistical patterns in historical data | Improves with more outcome data | Increases with training | Essential for edge cases and audit |
| Rules-Based Automation | Fixed, programmed criteria | None (static rules) | Constant | Required to update rules |
| Keyword Matching ATS | Keyword presence / absence | None | Constant | High (significant false negatives) |
| Structured Human Scoring | Defined rubric, human judgment | Requires training programs | Variable | The primary decision |
| Unstructured Human Screening | Intuition and pattern recognition | Inconsistent, bias-prone | Inconsistent | Unlimited |
The critical distinction between machine learning and rules-based automation is what happens when the world changes. A rules-based system continues applying its original rules indefinitely unless a human intervenes to update them. A machine learning model, retrained on new outcome data, adapts its predictions as the patterns in the data shift, making it structurally better suited to the dynamic, constantly evolving talent market environment.
What the Experts Say?
The promise of machine learning in hiring is not that it makes better decisions than humans. It is that it makes more consistent ones. Consistency, at scale, is where the talent quality advantage accumulates. Every recruiter has good days and bad days. A well-trained model does not.
– Dr. John Sullivan, Professor of Management, San Francisco State University; HR Thought Leader
How to Measure Machine Learning Effectiveness in Recruitment?
Formula
Screening Model Precision Rate (%) = (True Positive Predictions / (True Positive + False Positive Predictions)) x 100
Model Recall Rate (%) = (True Positive Predictions / (True Positive + False Negative Predictions)) x 100
Quality of Hire Lift (%) = (Avg. 12-Month Performance Rating of ML-Screened Hires / Avg. 12-Month Performance Rating of Manually Screened Hires) x 100
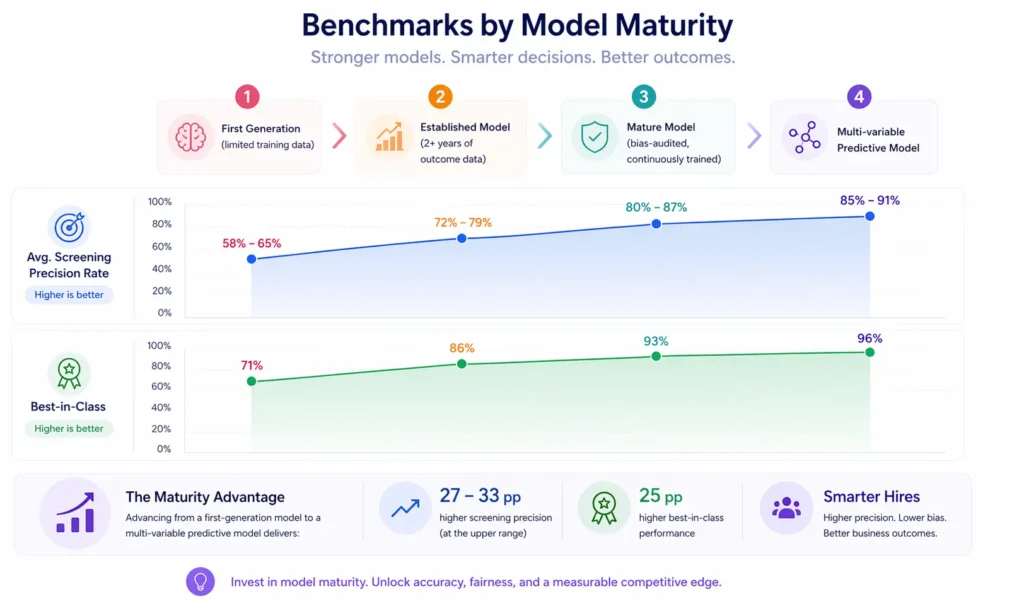
Benchmarks by Model Maturity
| Model Maturity | Avg. Screening Precision Rate | Best-in-Class |
|---|---|---|
| First generation (limited training data) | 58-65% | 71% |
| Established model (2+ years of outcome data) | 72-79% | 86% |
| Mature model (bias-audited, continuously trained) | 80-87% | 93% |
| Multi-variable predictive model | 85-91% | 96% |
Key Strategies for Effective Machine Learning Deployment in Recruitment
How Can AI and Automation Support Machine Learning in Recruitment?
Continuous Model Retraining Pipelines
The most effective ML deployment architectures in recruitment include automated retraining pipelines that update the model as new outcome data arrives, ensuring that the model’s predictive accuracy is continuously improving rather than degrading over time as the talent market and organizational context change. This automated retraining capability is what distinguishes enterprise-grade ML recruitment tools from point-in-time implementations.
Multi-Source Signal Integration
Advanced machine learning models in recruitment integrate signals across multiple data sources, including resume content, assessment scores, structured interview ratings, and reference feedback, to produce composite candidate quality predictions that are more accurate than any single-source model. The integration of structured interview data from interview scorecards into ML models is particularly valuable, as it connects the model’s predictions to the evaluative framework that hiring managers already use.
Attrition Prediction and Proactive Pipeline Management
Machine learning models trained on employee tenure, engagement, performance, and role history data can predict which employees are likely to leave within a 6-to-12-month window, enabling proactive candidate pipeline development for anticipated vacancies before those vacancies are officially open. This predictive capability converts reactive backfill hiring into planned hiring, substantially reducing the time-to-fill for high-attrition role types.
Explainable AI and Decision Transparency
Modern ML deployment standards in recruitment increasingly require explainable AI outputs, meaning model predictions accompanied by the factors that drove them, rather than black-box scores with no supporting rationale. Explainability is both a compliance requirement in many jurisdictions and a practical necessity for recruiter and hiring manager trust. Organizations that deploy explainable ML tools see significantly higher adoption rates and more appropriate human override behavior than those deploying opaque scoring systems.
Stop Juggling
10 Job Boards.
Search One
Your next role is already here. avua pulls opportunities from across the web into a single searchable feed; filtered by role, location, salary, and remote preference.
1.5 Million+
Active Jobs
380+
Job Categories
Machine Learning in Recruitment Through an Equity and Inclusion Lens
Training Data Bias and Its Downstream Effects
The most significant equity risk in machine learning recruitment applications is training data bias. When a model is trained on historical hiring decisions that reflected systemic bias, it will learn to replicate those decisions with high accuracy and at scale. This is not a hypothetical risk; Amazon’s 2018 disclosure that its internally developed ML hiring tool was systematically downgrading resumes that included the word women and had been trained to favor candidates resembling its historically male engineering workforce is the most widely cited example, but the pattern is industry-wide. Organizations deploying ML screening must treat bias auditing as an ongoing operational requirement, not a one-time implementation check.
Proxy Variable Discrimination in Candidate Scoring
Machine learning models can identify correlations between candidate attributes and historical hiring success that are statistically accurate but legally and ethically problematic as hiring criteria. A model trained on historical data may learn that candidates from certain zip codes, with certain educational backgrounds, or with certain career gap patterns are less likely to be hired, because those patterns correlate with historical selection decisions that were themselves discriminatory. Proxy variable auditing, which identifies whether model scoring factors correlate with protected class membership in ways that would constitute disparate impact, is a mandatory step in responsible ML recruitment deployment.
Candidate Transparency and the Right to Explanation
In jurisdictions including the European Union and several US states, candidates have legal or emerging legal rights to understand why an automated system made a decision that affected their employment opportunities. Organizations deploying ML screening tools must ensure that they can provide meaningful explanations of adverse automated decisions to candidates who request them. This requirement aligns with the explainable AI deployment standard described above and should be incorporated into vendor evaluation criteria for any ML-powered automated screening tool.
Common Challenges and Solutions
| Challenge | Solution |
|---|---|
| ML screening model producing low-quality shortlists despite high-volume input | Audit training data for historical bias and narrow demographic composition; redefine the outcome variable with a more precise performance measure |
| Hiring managers rejecting ML-generated candidate rankings | Invest in calibration sessions that demonstrate model prediction accuracy versus historical intuition-based screening; provide explainability data for model outputs |
| Model accuracy degrading over time without retraining | Implement an automated retraining pipeline with quarterly outcome data refresh; establish a model performance review cadence alongside the ATS review process |
Real-World Case Studies
Case Study 1: The E-Commerce Company
A 3,000-person e-commerce company processing 120,000 applications per year implemented an ML-powered screening model to replace a keyword-matching ATS filter that was producing a 34% pass rate with low-quality shortlists. The ML model, trained on 3 years of outcome data including 12-month performance ratings, produced a 22% pass rate with measurably higher quality. Recruiter time on manual screening fell by 68%, and quality-of-hire scores for the ML-screened cohort were 18% above the pre-implementation baseline. The model required three rounds of bias auditing during the first year to correct two proxy discrimination patterns identified in the training data.
Case Study 2: The Global Logistics Firm
A global logistics company implemented an ML attrition prediction model for its warehouse and operations workforce, which historically had 41% annual attrition. The model, trained on 4 years of tenure, engagement, schedule, and performance data, was able to predict 73% of voluntary departures at least 60 days before resignation with a precision rate of 81%. TA leaders used the prediction output to build proactive replacement pipelines for high-risk roles, reducing average time-to-fill for attrition backfills from 38 days to 19 days. Annual attrition cost reduction from faster backfill hiring was estimated at $2.4 million.
Case Study 3: The Professional Services Network
A professional services network deployed an ML-powered candidate matching tool for lateral hire searches across 14 practice areas. The tool integrated resume content, skills assessment scores, and structured interview ratings to produce composite candidate quality scores. Hiring managers who used the composite scores as their primary shortlist input made offers that were accepted 28% more often than those who used resume review alone, and their 12-month quality-of-hire scores were 21% above the firm’s pre-ML baseline. The tool required significant investment in structured outcome data collection before model training could begin.
Performance Indicators That Define Machine Learning Recruitment Success
Machine Learning Across the Talent Acquisition Lifecycle
Pre-Application: Candidate Matching and Sourcing
Machine learning models applied at the sourcing layer predict which professionals in the talent market are likely to be a strong fit for a role and likely to be open to a conversation, enabling recruiters to concentrate their outreach effort on the candidates most likely to convert. This pre-application ML layer is increasingly where the primary sourcing competitive advantage is built, as it determines the starting quality of the pipeline before any recruiter interaction occurs.
Screening: Automated Candidate Assessment
The application screening layer is where most organizations encounter machine learning for the first time, in the form of AI-powered CV screening or skills assessment scoring. At this layer, ML replaces or augments the manual screening process that historically consumed the largest proportion of recruiter time at the lowest average decision quality. The value is clear; the risks, primarily training data bias and precision-recall tradeoffs, require active management.
Interview: Scoring and Prediction Integration
Machine learning models can integrate structured interview scores, assessment results, and historical candidate pattern data to produce composite candidate quality predictions that support, rather than replace, hiring manager judgment. The critical design principle is that ML at the interview stage should function as a structured input to human deliberation, not as an automated decision.
Post-Hire: Outcome Measurement and Model Improvement
The post-hire stage is the most underinvested ML touchpoint in most organizations. The outcome data generated by new hire performance reviews, retention rates, and manager assessments is the training fuel that improves model accuracy over time. Organizations that close the data loop between hiring outcomes and ML model inputs build continuously improving predictive systems; those that do not see model accuracy plateau or degrade.
The Real Cost of Poor Machine Learning Implementation
| Implementation Approach | Screening Precision Rate | Recruiter Time Saved | Quality of Hire Impact |
|---|---|---|---|
| No ML (manual screening) | N/A (human variable) | None | Baseline |
| Basic keyword-matching ATS | 45-55% | Moderate | Neutral to negative |
| First-generation ML (unaudited) | 60-68% | High | Mixed (bias risk) |
| Mature, audited ML model | 82-91% | Very high | +15-22% above baseline |
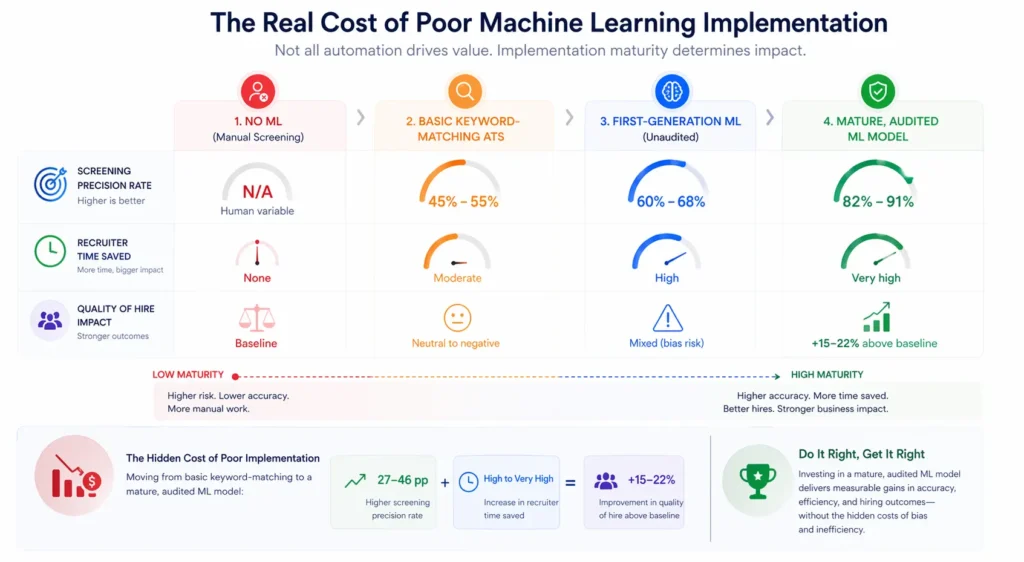
Quality of hire impact measured as 12-month performance rating differential from organizational average. Time saved assumes 50,000 annual applications.
Related Terms
| Term | Definition |
|---|---|
| Artificial Intelligence in Recruitment | The broad application of AI capabilities, including machine learning, natural language processing, and computer vision, to talent acquisition workflows |
| Algorithmic Bias | The systematic and repeatable errors in a computer system that create unfair outcomes due to biased training data or model design |
| Predictive Analytics | The use of statistical models and machine learning to forecast future outcomes based on historical data patterns |
| Automated Screening | The use of technology to evaluate and filter job applications based on predefined or learned criteria without manual review |
| Natural Language Processing | The AI field focused on enabling computers to understand, interpret, and generate human language, applied in recruitment to resume analysis and job description optimization |
Frequently Asked Questions
Is machine learning the same as AI in recruitment?
Machine learning is a subset of artificial intelligence. AI in recruitment includes machine learning models as well as other AI capabilities such as natural language processing, computer vision for video interview analysis, and rule-based automation. When vendors describe AI-powered recruitment tools, they are typically referring to machine learning models as the primary technical component.
How accurate are machine learning screening models?
Accuracy varies significantly by model maturity, training data quality, and how accuracy is measured. Well-trained, bias-audited ML models in mature deployments achieve precision rates of 80 to 90%, meaning 80 to 90% of candidates they flag as qualified are genuinely qualified when assessed through structured evaluation. First-generation models with limited or biased training data often perform closer to 60%, which may not represent a meaningful improvement over manual screening.
Can machine learning replace human recruiters?
No. Machine learning automates the pattern recognition and consistency layer of recruitment decision-making, specifically high-volume screening, matching, and initial scoring tasks. The judgment-intensive elements of recruitment, including relationship building with passive candidates, cultural fit assessment in context, and offer negotiation, remain irreducibly human. ML raises the quality floor; human judgment determines the ceiling.
How do I know if a machine learning recruitment tool is biased?
Request a bias audit report from any ML recruitment tool vendor before deployment, and run your own demographic differential analysis on outputs quarterly after deployment. Specifically, compare screening pass rates across gender, race, and age groups in the model’s output and investigate any statistically significant disparities. This analysis should be a standard requirement in procurement and ongoing operations, not an optional audit.
What data does a machine learning recruitment model need to be effective?
At minimum, the model needs structured candidate attribute data (resume content, assessment scores, application information) and consistently measured outcome data (which candidates were hired and how they performed at defined time points). The more complete and accurately labeled the outcome data, and the larger the historical dataset, the more accurate the model. Models trained on fewer than 1,000 labeled outcomes should be treated with significant caution.
Conclusion
Machine learning in recruitment is not the future of talent acquisition; it is the present.
The question is no longer whether to use it but how to use it responsibly, accurately, and in a way that genuinely improves hire quality rather than automating and accelerating historical bias.
The organizations that will build lasting competitive advantage from ML in recruitment are those that treat it as a data strategy investment requiring human oversight, bias auditing, and continuous outcome measurement, rather than as a software purchase that produces improvements automatically.
The algorithm is only as good as what you train it on and what you do with what it tells you.

