Recruiters do not read every resume.
At scale, that is not a failure of diligence, it is a mathematical reality. When hundreds of applications arrive for a single role, the question is not whether to filter automatically, it is how accurately that filtering happens. Resume parsing is the technology that makes that possible, and understanding how it works is increasingly important for both the hiring teams using it and the candidates being evaluated by it.
Resume parsing is the automated extraction and structuring of information from a resume, converting unstructured document data, work history, skills, education, contact details, into organised fields that an applicant tracking system or AI resume screening tool can read, rank, and act on. It sits at the very top of the hiring funnel, operating silently before any human ever opens a single application.
For recruiters running high-volume active sourcing campaigns, parsing accuracy directly affects the quality of candidates that surface. A parser that misreads formatting or misclassifies experience creates a flawed candidate pipeline from the very first filter, which is why the technology behind it matters more than most hiring teams realise.
Resume parsing also has direct implications for blind hiring and bias in hiring practices, since the fields a parser prioritises and the ones it discards can quietly embed the same biases that structured hiring processes are designed to remove.
The core metric governing resume parsing performance is the Parse Accuracy Rate: the proportion of data fields correctly extracted and categorized across a batch of processed resumes.
Parse Accuracy Rate (%) = (Correctly Extracted Fields / Total Expected Fields) × 100
Top enterprise parsing solutions and modern AI-native ATS platforms achieve Parse Accuracy Rates of 88–95%. The industry average across all deployed parsing tools sits closer to 72%. The gap is almost entirely explained by the sophistication of the underlying NLP model and the quality of training data, not by the complexity of the resumes being processed.
What is Resume Parsing?
Resume parsing is the automated technology process that reads an incoming resume document, regardless of format, whether PDF, DOCX, or plain text, identifies and extracts key information fields, normalises that data against a standardised schema, and outputs a structured candidate record that can be searched, filtered, ranked, and compared within a recruitment management system.
The candidate profile produced by a resume parser typically includes: personal identification data, current and previous job titles, employer names and employment durations, educational qualifications and institutions, technical and soft skills, certifications and licenses, and contact information. Advanced parsing systems also extract inferred data such as industry categorisation, seniority level estimation, and career progression patterns that the resume does not explicitly state.
What makes resume parsing more than a sophisticated data entry shortcut is its position in the hiring workflow. Every downstream automated screening decision, candidate ranking, and shortlist is built on the foundation of parsed data. A parser that misreads a job title or drops a qualification from a candidate’s record does not just create an administrative error, it creates a hiring decision distortion that may eliminate a qualified candidate before any human has reviewed their application.
Why Resume Parsing Is a Game-Changer for Modern Talent Acquisition?
The question of whether to invest in quality parsing technology sounds administrative on the surface. It is actually a talent acquisition strategy decision disguised as a software procurement question. The organizations that understand this distinction are the ones outpacing their competitors on hiring speed, candidate quality, and recruiter productivity simultaneously.
Before modern AI-powered resume parsing, hiring teams faced an unresolvable tension: speed versus thoroughness. Reviewing applications manually at speed produced missed qualified candidates; reviewing them thoroughly at scale produced hiring timelines that could not keep pace with competitive markets. The result was a chronic compromise, either good hires found slowly, or adequate hires found quickly. Neither is a sustainable recruitment strategy in a talent market where top candidates make decisions within days of entering a process.
Resume parsing resolves that tension by removing the tradeoff. A well-implemented parsing layer can process 500 applications in the time a recruiter would manually review three. Critically, those 500 applications are not skimmed, they are structured, and each candidate record is equally complete, equally searchable, and equally accessible for evaluation and comparison. The recruiter’s time is then concentrated on the judgment work that genuinely requires human expertise, not on data extraction from PDFs.
The market data is unambiguous. According to LinkedIn’s Global Talent Trends research, organizations using AI-assisted parsing and screening tools reduce their average time-to-shortlist by 41% compared to manual-review workflows. More significantly, they report 28% higher recruiter satisfaction scores, because recruiters are spending their time on conversations and evaluations rather than spreadsheet administration.
A concrete benchmark makes the efficiency case stark. iCIMS data shows the average corporate job opening attracts 250 applications. Without parsing, a three-person recruiting team managing 30 open roles simultaneously would need to manually process 7,500 resumes. At five minutes per resume, which is optimistic for a thorough read, that is 625 hours of manual data extraction before a single candidate interview conversation begins. Resume parsing converts that 625-hour bottleneck into a few minutes of processing time, freeing the equivalent of 15-plus recruiter-weeks per hiring cycle for higher-value work.
The quality case for investment is equally compelling. Structured, parsed candidate data enables capabilities that are simply impossible with manually processed resumes: skill-gap analysis across the full applicant pool, pattern recognition linking candidate profile variables to historical hire performance, and automated matching against role requirements at a level of granularity that no manual review process can replicate at scale.
For talent acquisition leaders, the practical conclusion is that resume parsing is not a cost centre tool, it is a competitive capability. Organizations that have implemented high-accuracy parsing technology are not just processing resumes faster; they are making better hiring decisions because the data underpinning those decisions is complete, accurate, and comparable across hundreds of candidates simultaneously.
The ROI calculation is direct to model. For a 200-person company making 40 hires per year, investing in enterprise-grade parsing technology versus maintaining manual resume processing saves approximately 1,200 recruiter-hours annually. At a fully loaded recruiter cost of $65 per hour, that is $78,000 in recovered capacity, before accounting for the candidate quality improvements produced by more thorough, consistent data extraction across every application, not just the ones a recruiter happened to read carefully on a given afternoon.
Your Resume Isn’t Getting Read
Let’s Get That Fixed!
75% of resumes get auto-rejected. avua’s AI Resume Builder optimizes formatting, keywords, and scoring in under 3 minutes, so you land in the “yes” pile.
The Psychology Behind Resume Parsing
Cognitive Offloading and Recruiter Efficiency
The human brain’s working memory has a limited capacity for parallel information processing. When recruiters manually read and evaluate resumes, they are performing two cognitively demanding tasks simultaneously: data extraction (what does this resume contain?) and evaluation (does this candidate meet our criteria?). Resume parsing performs the extraction task automatically, enabling the recruiter to concentrate entirely on evaluation. This cognitive offloading produces not just faster review but more accurate evaluation, because the recruiter is no longer dividing cognitive attention between two competing demands at the exact moment judgment quality matters most.
Automation Bias and the Risk of Uncritical Trust
The most significant psychological risk in resume parsing deployment is automation bias: the tendency to over-trust automated system outputs without applying critical human review. Recruiters who treat parsed candidate records as fully authoritative, without reviewing the source document for context, nuance, or parsing errors, are effectively substituting the parser’s limitations for their own judgment. A parser cannot read a career narrative; it can only extract discrete data points.
A candidate whose non-linear career path reveals a compelling pattern of deliberate skill-building may look weak in a parsed profile and exceptional to a thoughtful human reader. The organizations that extract maximum value from parsing technology use it as a starting point for evaluation, not a substitute for it.
Anchoring Effects in Structured Data Review
Parsed candidate records create a standardized, structured presentation of candidate information that influences how recruiters evaluate what they see, a cognitive mechanism known as anchoring. When a recruiter reviews a parsed profile with a clearly labelled “years of experience” field showing 4 years, that number anchors their subsequent evaluation of everything else in the profile. The anchoring effect works in both directions: it can elevate a candidate who looks strong on quantifiable metrics (years, titles, institutions) even when qualitative evidence suggests a poor fit, or undervalue a candidate whose unconventional background does not parse to impressive numbers but represents exactly the profile the role needs.
Resume Parsing vs. Related Recruitment Technologies
| Technology | Primary Function | Output | Speed | Accuracy | Best For |
|---|---|---|---|---|---|
| Resume Parser | Structured data extraction | Candidate data record | Very fast | 72-95% | ATS intake, high volume |
| Manual CV Review | Human interpretation | Recruiter assessment | Slow | Variable | Senior, niche, or low-volume roles |
| AI Resume Screening | Scoring against criteria | Ranked candidate list | Fast | High with training data | Mid-level volume screening |
| Keyword Matching | Pattern matching | Pass/fail filter | Very fast | Low (context-blind) | Basic ATS pre-filtering |
| Assessment-Based Screening | Skills and behaviour testing | Scored evaluation | Moderate | High for measured dimensions | Technical and specialist roles |
The critical distinction between a resume parser and an AI screening tool is function and sequence. A resume parser processes the document: it reads what is there and structures it. An AI screening tool evaluates the structured data against criteria: it decides which candidates are most likely to be qualified. Parsing is the prerequisite; screening is the downstream application. Organizations that conflate the two, expecting their parser to perform the work of a screening algorithm, get poor performance from both.
What the Experts Say?
Resume parsing is the invisible infrastructure of modern recruitment. When it works accurately, nobody notices. When it fails, dropping qualifications, misreading job titles, rejecting formatting it cannot interpret, the cost is paid in missed candidates and wasted recruiter time, often without anyone realising where the loss occurred.
– Dr. John Sullivan, Professor of Management, San Francisco State University; Author, Rethinking Corporate Staffing
How to Measure Resume Parsing Effectiveness?
Formula
Parse Accuracy Rate (%) = (Correctly Extracted Fields / Total Expected Fields) × 100
Format Success Rate (%) = (Successfully Parsed Documents / Total Submitted Documents) × 100
Field Completion Rate (%) = (Populated Candidate Fields / Total Expected Fields per Profile) × 100
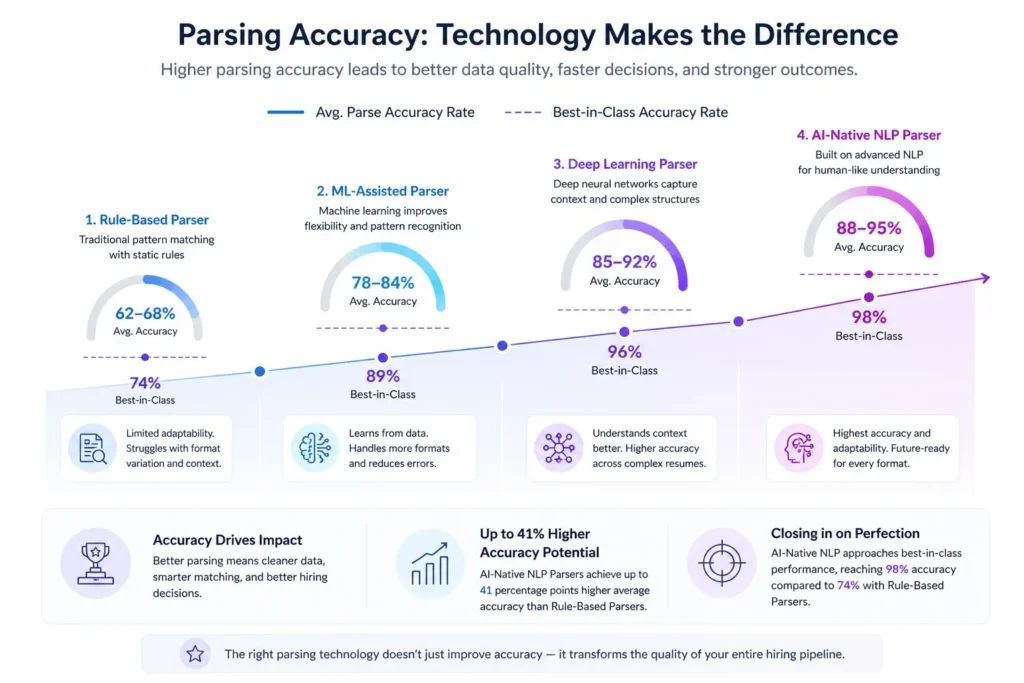
Benchmarks by Parsing Technology Type
| Parsing Technology | Avg. Parse Accuracy Rate | Best-in-Class |
|---|---|---|
| Rule-Based Parser | 62-68% | 74% |
| ML-Assisted Parser | 78-84% | 89% |
| Deep Learning Parser | 85-92% | 96% |
| AI-Native NLP Parser | 88-95% | 98% |
Key Strategies for Effective Resume Parsing
How Can AI and Automation Enhance Resume Parsing?
Contextual Natural Language Processing
Modern AI parsers move beyond keyword extraction to contextual understanding. They recognise that “led a cross-functional team of 12 to deliver a $2M product launch” is evidence of project leadership, stakeholder management, and budget ownership, even though none of those exact terms appear in the text. Natural language processing (NLP) models trained on large corpora of professional language infer competencies, responsibilities, and experience levels from how candidates describe their work, producing richer, more accurate structured profiles from the same source documents.
Multi-Format Document Intelligence
AI-powered document intelligence handles the format diversity of modern resume submissions, PDFs with embedded graphics, LinkedIn profile exports, scanned paper resumes, and video resume transcripts, in a unified parsing pipeline. Rather than failing on non-standard inputs, these systems adapt their extraction strategy to the document structure they encounter, maintaining high accuracy across format variation that would defeat a rule-based parser entirely.
Automated Skill Taxonomy Mapping
Advanced parsing platforms map extracted skills against standardised taxonomies, including the O*NET skills framework and the European Skills and Competences framework, enabling genuine comparison of candidates who describe equivalent skills in different language. This automated normalisation makes skill-based filtering and candidate comparison meaningful at scale rather than purely literal.
Continuous Learning and Parser Improvement
AI parsing systems configured for continuous learning improve from recruiter corrections: when a recruiter manually corrects a parsing error, the correction feeds back into the model as training data. This improvement loop progressively raises accuracy over time, specifically on the document types and role categories most common to that organization’s hiring activity. According to SHRM, organizations that actively manage their parsing systems through continuous learning protocols achieve Parse Accuracy Rates 15-20 percentage points higher than those using static parsers on the same candidate volumes.
Stop Juggling
10 Job Boards.
Search One
Your next role is already here. avua pulls opportunities from across the web into a single searchable feed; filtered by role, location, salary, and remote preference.
1.5 Million+
Active Jobs
380+
Job Categories
Resume Parsing and Equitable Hiring Practices
Format Bias and Candidate Equity
The most structurally significant equity issue in resume parsing is format bias: parsers trained predominantly on resumes following standard corporate Western professional formats systematically underperform on resumes from candidates who do not conform to that template.
First-generation professionals, international candidates, career changers, and candidates from underrepresented communities are more likely to submit resumes in non-standard formats, meaning parsing failures disproportionately affect the candidate populations that diversity hiring strategies are designed to reach. Auditing parse accuracy by submission format type, and building manual review pathways for underperforming format categories, is the primary operational corrective.
Credential-Focused Parsing and Skill Signal Suppression
Parsers optimised for credential extraction, degrees, certifications, employer names from target company lists, reproduce the credential bias of the organizations whose historical data trained them. A parser that weights a degree from a target university list as a strong positive signal is not assessing candidate quality; it is automating a hiring preference. Configuring parsers to weight demonstrated skill signals alongside credentialing signals supports more equitable evaluation of candidates from non-traditional educational backgrounds, consistent with skills-first hiring strategies.
Accessibility of the Application Experience
Parse accuracy is partly a function of how clearly candidates can communicate their experience in the application format provided. Organizations that build accessible, mobile-optimized application experiences with clear resume format guidance produce better-structured inputs for parsing, which directly improves accuracy for all candidates. This is not only a DEI intervention; it is a data quality investment that benefits the entire candidate pipeline from intake through shortlist.
Common Challenges and Solutions
| Challenge | Solution |
|---|---|
| High parse failure rate on non-standard resume formats | Implement a fallback manual data entry process for failed parses; upgrade to AI document intelligence tools that handle format variation without failure |
| Parsed data missing key fields for specific role types | Configure field extraction templates per role category; add targeted application form prompts guiding candidates to include commonly missed information |
| Parser accuracy degrading over time without apparent cause | Schedule quarterly parse accuracy audits; check for shifts in applicant resume format trends and retrain the model on recent data samples |
Real-World Case Studies
Case Study 1: The Global Logistics Company
A global logistics company processing 4,000 applications per month across 12 countries faced a critical parsing challenge: resumes arrived in 7 languages, multiple date formats, and widely varying structural conventions. Their legacy rule-based parser achieved a 58% accuracy rate on non-English submissions, causing thousands of qualified candidates to be incorrectly filtered at intake. They migrated to a multilingual NLP parsing platform trained on resume data from each target market. Parse Accuracy Rate across all language groups improved to 89%, and the proportion of non-native-language candidates advancing to shortlist increased by 34%, diversifying their candidate pipeline at zero additional sourcing cost.
Case Study 2: The Technology Scale-Up
A 300-person technology company growing rapidly found that their ATS parser was consistently failing to extract skills listed in visual tag-cloud formats or graphical competency charts, a format popular among UX and design candidates. The parser was interpreting the graphic section as an image rather than text, leaving those profiles with empty skill fields and causing them to be filtered before human review. The company introduced a candidate-facing format guide at the application stage and configured a manual review queue for profiles with Field Completion Rates below 75%. Designer and UX candidate advance rates from screening to interview improved by 29% within two hiring cycles.
Case Study 3: The Healthcare Network
A regional healthcare network found that 22% of nursing applications were being filtered before human review because the parser failed to recognise state-specific nursing licence abbreviations. It correctly parsed “RN” but not “CRRN,” “APRN,” or the state-specific licence format used across four of their target markets. Working with their ATS vendor to extend the qualification taxonomy with healthcare-specific credentialling terms reduced the filter failure rate for nursing applications from 22% to 4%. A six-month nursing vacancy crisis was partially resolved through the qualified candidate pipeline that had previously been invisible to their screening process.
Essential Performance Indicators for Resume Parsing Success
Resume Parsing Across the Hiring Lifecycle
Pre-Application: Form and Format Design
Resume parsing effectiveness begins before a candidate submits anything. Application form design, the fields included, the format guidance provided, the document types accepted, directly determines the quality of the input the parser receives. Organizations that invest in candidate-facing application experience design, with clear guidance on how to structure submissions for optimal processing, improve their parse accuracy rates without changing a line of parser configuration.
Application Intake: The Parsing Moment
The core parsing event converts a submitted document into a structured candidate record. At this stage, the critical operational considerations are processing speed (candidates should not wait hours for submission confirmation), format compatibility (the parser should handle all accepted formats without failure), and error handling (failed parses should trigger a defined review process rather than silent rejection that the candidate never learns about).
Screening and Shortlisting: Parsed Data in Action
The parsed candidate record is the data foundation for every subsequent screening decision. Keyword filters, skill-match algorithms, experience-floor filters, and AI ranking models all operate on parsed data. If the parsed data is incomplete or inaccurate, these downstream processes produce flawed outputs, filtering qualified candidates based on data that does not accurately represent their application. Parse quality is screening quality.
Post-Hire: Closing the Data Loop
The most underutilized application of resume parsing data is post-hire analysis. Comparing the parsed profiles of placed candidates who succeeded at the 12-month mark against the profiles of candidates who were rejected at screening identifies which parsed data signals are genuinely predictive of performance and which are noise. This closed-loop analysis improves both the parser configuration and the screening criteria applied to parsed data in future hiring cycles.
The Real Cost of Poor Resume Parsing
| Scenario | Parse Accuracy Rate | Qualified Candidates Lost at Intake | Estimated Annual Cost Impact (500 applications/month) |
|---|---|---|---|
| Legacy rule-based parser | 62% | ~23% of qualified candidates | $180,000+ in re-sourcing and vacancy costs |
| Standard ML parser | 78% | ~12% of qualified candidates | $95,000 |
| AI-native NLP parser | 92% | ~3% of qualified candidates | $24,000 |
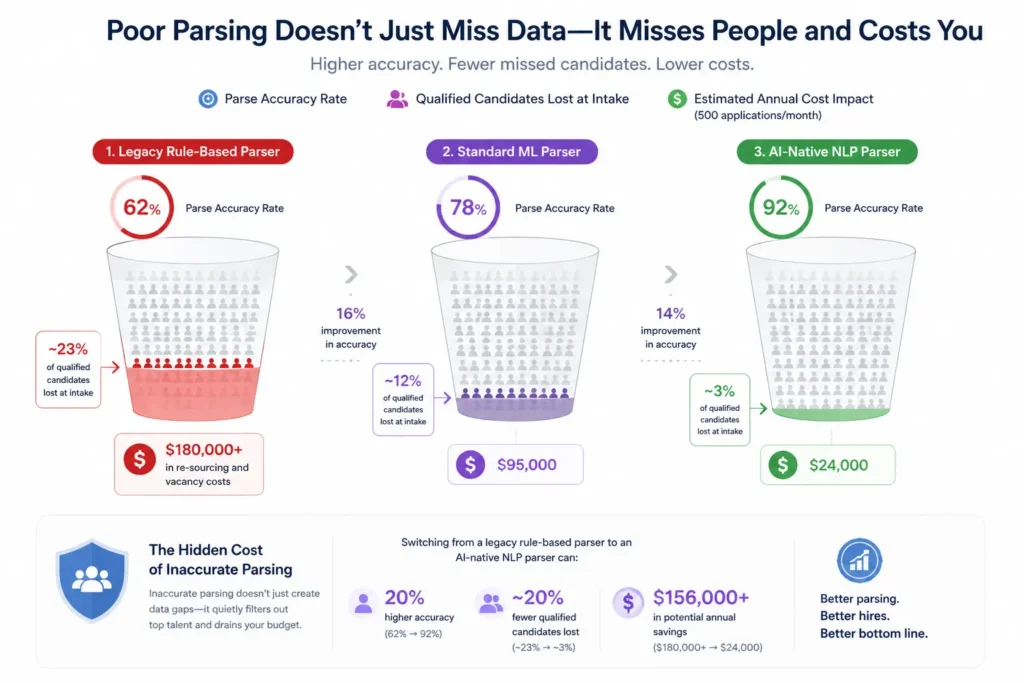
Costs estimated based on average cost-per-hire of $4,800 and vacancy productivity loss of $300/day per unfilled role. Qualified candidate loss percentage derived from field-level accuracy gap analysis across parser technology types.
Related Terms
| Term | Definition |
|---|---|
| Applicant Tracking System (ATS) | Software platform for managing job applications, candidate data, and recruitment workflows at scale |
| AI Resume Screening | Automated evaluation of parsed candidate profiles against defined role criteria using machine learning models |
| Natural Language Processing (NLP) | AI technology that enables computers to understand and interpret human language in context rather than through literal matching |
| Candidate Pipeline | The structured pool of candidates at various stages of engagement within a recruitment process |
| Data-Driven Recruiting | A recruitment approach using quantitative data and analytics to inform sourcing, screening, and hiring decisions |
Frequently Asked Questions
What exactly does resume parsing do?
Resume parsing reads a submitted resume document, identifies and extracts key data fields (name, contact information, work history, education, skills, certifications), normalises that data against a standard schema, and outputs a structured candidate record that can be stored, searched, and evaluated within an ATS or recruitment platform.
How accurate are modern resume parsers?
Accuracy varies significantly by technology generation. Rule-based parsers achieve 62-68% accuracy. Machine learning parsers reach 78-84%. AI-native NLP parsers achieve 88-95% accuracy on well-formatted documents. Non-standard formats, graphics-heavy designs, and non-English-language documents consistently produce lower accuracy across all parser types.
Does resume parsing disadvantage certain candidates?
Yes, if not carefully managed. Parsers trained on standard corporate resume formats underperform on non-standard submissions, which are more common among candidates from underrepresented groups. Organizations should audit parse accuracy across submission format types and build human review pathways for profiles with low Field Completion Rates.
Can candidates optimise their resumes for better parsing?
Candidates can improve how their resumes are parsed by using clean, standard formatting without tables or text boxes, saving files as PDF or DOCX, using clear section headers, and spelling out abbreviations on first use. This is not gaming the system, it is ensuring the parser accurately represents the application to human reviewers.
What is the difference between resume parsing and resume screening?
Resume parsing extracts and structures data from a resume document. Resume screening evaluates that structured data against role requirements to determine which candidates should advance. Parsing is the data preparation step; screening is the evaluation step. Both are required for effective automated intake, but they are distinct technical functions that should be evaluated separately.
Conclusion
Resume parsing is not merely a feature of a modern ATS, it is the foundational layer on which every downstream hiring decision is built.
Organizations that invest in high-accuracy parsing technology, audit their parse performance regularly, and configure their systems to handle the full diversity of candidate submission formats are not just processing resumes faster.
They are ensuring that hiring decisions are made on accurate, complete, and equitable data, rather than on the accidents of document formatting or the limitations of a parser that was never properly configured for the roles it is screening. In a market where qualified candidates are scarce and hiring speed is a genuine competitive differentiator, the quality of your resume parsing infrastructure is, functionally, the quality of your candidate pipeline.
Treat it accordingly.

